

Gil Haberman, Senior Director of Product Marketing
Scaling and Operationalizing AI in Government
Today at AI World Government 2021, Andy Hock our VP of Product, shared our vision of how Cerebras Systems can empower government organizations to harness the power of AI and develop unprecedented capabilities in Defense, Energy, Climate, and Health Services.
While AI is in its infancy, many government organizations are already adopting sophisticated models to improve critical capabilities. For example, AI is used in smart language, signal, and image processing for science and security, AI-guided drug development, record analytics, and improved weather models.
However, public datasets are massive and groundbreaking applications require large models that take weeks or months to train. As models rapidly get larger this challenge significantly inhibits research progress, driving costly delay of new capabilities; the datasets are available but deep insights and key decisions are delayed or lost.
The reason is primarily that AI models are very compute intensive. Existing, general-purpose processors were not built for this work at large scale, so existing solutions are suitable but far from optimal. For large models, clusters of processors are stitched together in attempt to speed up performance.
Yet this approach doesn’t scale: For instance, looking at a prominent GPU MLPerf 1.0 result, we see that increasing device count to 512 only delivers 68x speed-up. As more devices are used, the inefficiency grows, including massive waste in energy. In an attempt to make the most of these clusters, researchers are forced to continually fine-tune their models, making the solution increasingly costly to program and operate. As a result, we need more compute per-device, and to find a way to reduce the reliance on scale-out data parallel architectures.
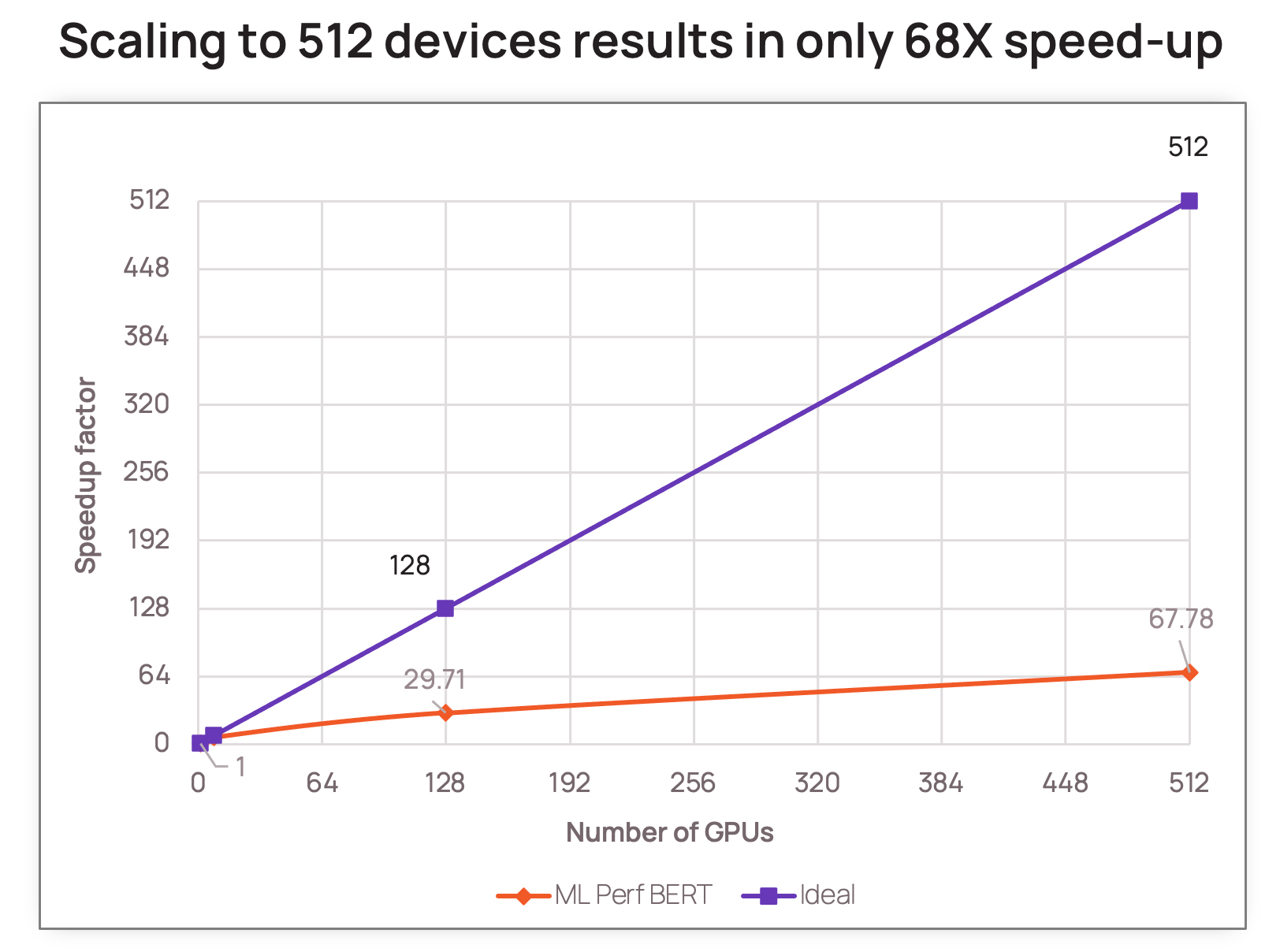
Source: Leading GPU MLPerf 1.0 results
We took on this challenge at Cerebras and delivered the largest chip ever built, the backbone of the fastest AI Accelerator in the world. Our latest CS-2 system packs the compute power of 850,000 AI-optimized cores on a single chip, along with orders of magnitude more memory and interconnect bandwidth than traditional systems. These purpose-built performance advantages allow the CS-2 to accelerate deep learning models far beyond what GPUs and CPUs are capable of.
A single CS-2 provides the wall-clock compute performance of an entire cluster of GPUs, made up of dozens to hundreds of individual processors, at a fraction of the space and power. For government organizations, this means faster insights at lower cost. For the ML researcher, this translates to achieving cluster-scale performance with the programming ease of a single device.
For example, we have been working with U.S. Department of Energy’s Argonne National Laboratory (ANL) on accelerating drug and cancer research. As Rick Stevens, ANL’s Chief Scientist, put it: “We are doing in a few months what would normally take a drug development process years to do. Computing power was almost equivalent to that of a cluster of computers with up to 300 GPU chips.” The massive acceleration of the Cerebras system empowers researchers to innovate much faster and drives breakthroughs that would otherwise not be discovered.
Do you think we can help your organization achieve similar outcomes? Want to learn more about our approach? Click here to connect with our team!

Related Posts
Cerebras Breaks Exascale Record for Molecular Dynamics Simulations
Cerebras has set a new record for molecular dynamics simulation speed that goes…


Supercharge your HPC Research with the Cerebras SDK
Cerebras SDK 1.1.0, our second publicly available release, includes initial…