
A few years ago, we thought autoregressive natural language processing models with 100 million parameters were massive. Now, Cerebras makes it not just possible, but easy, to continuously train and fine-tune the powerful open source GPT-J model with six billion parameters on a single device. In this article, I’ll examine why these models are so exciting, how GPT-J works and just how simple it is to train it using a single Cerebras CS-2 system.
The rise of large language models
Over the past several years we’ve observed exponential growth of Natural Language Processing (NLP) models trained in a self-supervised manner, with massive volumes of unlabeled data (Figure 1). From GPT-1 to BERT to GPT-2 to T5, GPT-3, GPT-J, GPT-NeoX and MT-NLG, the number of parameters has exploded from hundreds of thousands to hundreds of billions. These models demonstrate an ability to perform amazingly well on a wide variety of NLP tasks, such as long document summarization, sentiment analysis, and question answering, to name just a few.

A typical approach to get smaller models (such as BERT) to perform well on different tasks, is to break training in two stages: 1) pre-training of a general model with very large unannotated dataset and 2) fine-tuning of a task-specific model with small task-specific labeled dataset. During the first stage, a model is exposed to large amounts of written texts to learn to understand context, relationships between words and semantics of every given word in a sentence. During this self-supervised pre-training, model weights are adjusted for general text understanding, as the model learns to map every word in a sentence to its context-aware representation.
Then, during the fine-tuning stage, a task-specific model can be built on top of a pre-trained model without substantial model modifications and with limited amount of labeled data. The same pre-trained model can be used to derive many different task-specific models.
Extreme-scale models, those with hundreds of billions of parameters, have been shown to perform reasonably well on a variety of tasks even without the second fine-tuning stage, in so called zero-shot setting, when a model is tested on a new task which hasn’t been seen by the model before. But these extreme-scale models are extremely expensive and hard to train and require extremely large, “clean” datasets, i.e. incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data have been removed. These models require supercomputer-scale resources to train, with thousands of GPUs connected via high-speed network interconnects. Only a few organizations can afford (and manage) to train these extreme-scale models from scratch. And until recently, once trained, these massive models (like OpenAI’s GPT-3) have been made accessible to the world only for predictions as-a-service via the cloud. It wasn’t possible to get the pre-trained weights for your own adjustment and use. Performing inference using these general-purpose pre-trained models in the cloud is neither cheap nor guaranteed to perform well a new task with domain-specific proprietary data. It also has additional risks, such as potential data and IP leakage when used with sensitive data.
That’s when open-source efforts like GPT-J by EleutherAI came to the rescue. EleutherAI released trained weights for the GPT-J model in 2021 and since than GPT-J attracted significant attention from both industry and academia. Although GPT-J has “only” 6B parameters compared to GPT-3’s 175B, its accessibility made a huge difference. It has been shown than once fine-tuned, GPT-J can do better than non-fine-tuned GPT-3 on a number of tasks. Although GPT-3 has been trained on a very large corpus, it is still general-purpose – it lacks knowledge in specific domains and is not as capable on non-English data. So, it makes perfect sense that one can get a better task-specific model by fine-tuning although a smaller, but still massive, model, like GPT-J. Also, a trained GPT-J model, because its smaller, also requires fewer compute resources when used for inference. Most importantly, accessible pre-trained weights give user all the freedom and flexibility to adjust that model to specific needs and use local versions of the model rather than send inference data to the cloud.
GPT-J in more detail
Let’s dive a bit deeper into GPT-J. It is a “GPT-like” autoregressive language model. GPT-like means that like GPT it consists of attention and feed-forward blocks, and like GPT it is autoregressive – given part of a sentence (or just a special token indicating the start of a sentence) the model predicts the following tokens, one by one. A canonical configuration of the model, GPT-J-6B, has 6B parameters and it is one of the largest open alternatives to OpenAI’s GPT-3. GPT-J-6B has been trained by EleutherAI on The Pile, an 800MB dataset carefully assembled and curated from a large number of text datasets from different domains.
The design of the GPT-J model is similar to GPT-3 with a few notable differences (Figure 2):
-
- GPT-J introduces parallel decoder architecture, when attention and feed-forward layers in decoder are computed in parallel and then the results are added, as opposed to computing them sequentially by feeding attention output into feedforward layer, as in standard transformer models. This architectural change has been introduced by EleutherAI to achieve higher throughput with distributed training, as it decreases communication. With traditional design, residual attention with op-sharding requires one all-reduce in the forward pass and one in the backward pass[i]. By computing attention and feedforward layers in parallel, the results can be reduced locally before performing a single all-reduce. This leads to an average 15% increase in throughput on traditional hardware without noticeable impact on convergence.
- GPT-J model uses Rotary Position Embeddings as in, which is shown to result in better model quality in tasks with long texts[ii]. We use 25% rotary embeddings, as it is shown to get a good balance between computational efficiency and model performance (convergence)[iii].
- GPT-J uses dense attention instead of efficient sparse attention used in GPT-3. EleutherAI stated that dense attention has been used for simplicity, as sparse attention would not have significantly improved throughput at this scale.
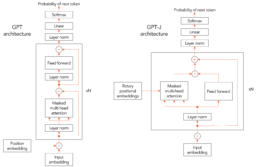
Although most of these design choices have been made with a single purpose of improving throughput on traditional hardware and are not expected to impact throughput on the Cerebras CS-2, we replicated GPT-J design in our implementation to be able to leverage available trained weights.
Use cases
As mentioned above, massive autoregressive language models in general, and GPT-J in particular, can be used for a variety of applications. Some important ones are
-
- Summarization
- Question answering
- Autocorrection and autocompletion
- Sentiment analysis
- Chat bots
- Relation extraction
Let’s look at summarization in more detail.
Summarization
It is harder and harder to keep up with constantly growing volumes of text data. Arxiv claims that they receive up to 1,200 new submissions daily, many news articles are produced daily, millions of ordinary people produce tweets and blog posts, also daily. And in many domains every single detail matters, so we produce long documents and reports to capture all these details, like in clinical study reports, which are “typically very long, providing much detail about the methods and results of a trial”, or in legal documents. Having a machine that is capable of producing accurate grammatically correct and coherent shorter versions of one or several documents can really help to navigate this flood of data in many domains. GPT-J is capable of abstractive summarization, pre-trained model has its limitations (length of a document one could feed into the model is one of those), so ability to fine-tune on longer documents and on specific domain is very important.
Fine-tuning GPT-J made easy for the first time with Cerebras
With GPT-J we have accessible weights and an ability to tune the model for specific domains and tasks. Fine-tuning is much, much less computationally expensive than pre-training – you would typically fine-tune on a much smaller dataset, so compute requirements for fine-tuning is a tiny fraction of those for pre-training. However, it is still cumbersome and hard for a 6B-parameter-model. These large-scale GPT models are commonly trained with the Adam optimizer which stores two terms, momentum and variance, per every model parameter, and when trained in mixed precision typically needs total of 16 bytes per parameter to store model weights, gradients and optimizer states. With 6B parameters this results in 96GB. It means that this model doesn’t fit into memory of modern accelerators and requires multiple accelerators and complicated model-parallel distribution just to load the model for continuous training or fine-tuning.
Thanks to our groundbreaking weight streaming execution mode, the Cerebras CS-2 has no such limitations. With our implementation of GPT-J it is now easy to load a publicly available GPT-J checkpoint and tune this model on a single CS-2 with a custom domain-specific or task-specific dataset.
Michael James, Chief Architect, Advanced Technologies, and Cerebras Co-Founder gives a great explanation of how our weight streaming technology leverages the CS-2 system’s vast amount of sparse tensor compute power in this blog post. The short version is that it turns our normal execution mode inside out. Instead of storing model weights on our Wafer-Scale Engine, we store activations instead, and process one layer at a time. This enables us to handle more than a billion parameters per layer. We know this technique scales – linearly! – to handle models with hundreds of trillions of parameters, so we have an architecture ready for whatever AI researchers can throw at us for many years to come.
Conclusion
Just a few years ago, state-of-the-art, autoregressive natural language processing models had 100 million parameters and we thought that was massive. Now, Cerebras makes it not just possible, but easy, to continuously train and fine-tune the powerful open source GPT-J model with six billion parameters on a single CS-2 system using our groundbreaking weight streaming execution mode.
If you’ve been thinking about what GPT-J can do for your work, but have been put off by the intractable compute demands on conventional infrastructure, now is the time to get in touch with us. The sky is the limit!
Natalia Vassilieva, Director of Product, Machine Learning | June 22, 2022
Resources
Documentation
-
- For a complete list of features released in each version of CSoft, please refer to our Release Notes
- Developer documentation, including code workflow tutorials
- Cerebras Reference Implementations
Articles
References
[i] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, Bryan Catanzaro, “Megatron-LM: Training multi-billion parameter language models using model parallelism”, arXiv, September 2019 https://arxiv.org/abs/1909.08053
[ii] Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, Yunfeng Liu, “RoFormer: Enhanced Transformer with Rotary Position Embedding”, arXiv, 2021 https://arxiv.org/abs/2104.09864
[iii] “Mesh-Transformer-JAX: Model-Parallel Implementation of Transformer Language Model with JAX”, GitHub, May 2021, https://github.com/kingoflolz/mesh-transformer-jax
Related Posts
Cerebras Breaks Exascale Record for Molecular Dynamics Simulations
Cerebras has set a new record for molecular dynamics simulation speed that goes…


Supercharge your HPC Research with the Cerebras SDK
Cerebras SDK 1.1.0, our second publicly available release, includes initial…